
Call us in Seattle
+1 (800) 871-6550
ブログ:
IMX8X GPU FFT 运算
2019年3月18日月曜日
伴随着 4G 网络的大范围覆盖,已经即将到来的 5G 网络,边缘计算越来越多地开始进入人们的视野。相比于云计算的云端集中处理,边缘计算能够就地进行复杂数据的计算,并迅速作出决策。由于免去了数据的远程传输,边缘计算能够带来更低的延时、更可靠的数据安全。但这也对边缘计算设备带来更大的挑战,特别是计算性能。下面我们将介绍如何在 Toradex Colibri iMX8X 计算机模块上利用 GPU 加速运算快速傅里叶变换 FFT。
Colibri iMX8X 模块是 Toradex 基于 NXP iMX8 X 推出的紧凑型 Arm 核心板。iMX8X 具有最高4核 64-bit Armv8-A Cortex-A35,主频1.2GHz。Colibri iMX8X板载 WIFI 和蓝牙,使其能够便捷地连接网络和移动设备。集成 Cortex-M4 处理器, iMX8X 除了支持 Linux 等高级操作系统外,还可以同时运行 FreeRTOS,执行低功耗或者实时应用。丰富的工业接口如 CAN、SPI、UART、双以太网等,便于连接外部设备。 GC7000Lite GPU 图形处理单元,峰值算力 64 GFLOPS,支持OpenCL、OpenGL 以及 Vulkan ,方便用户利用 GPU 资源。使用 GPU 处理计算密集型数据,除了能够提高效率外,还可以有效降低 CPU 负荷,保证用户应用流畅运行。接下来你将会了解如何使用 OpenCL 在 iMX8X 上的 GPU 实现 FFT 计算。
搭建开发环境
在撰写本文时,Toradex 基于 imx-4.9.123 Linux BSP 提供 Colibri iMX8X 的支持。由于是早期发布阶段,Toradex SDK 并没有集成使用 OpenCL 在 GPU 计算FFT的库文件,如 GLi、Tclap 等。为了生成完整的 SDK ,我们将使用NXP 标准的 Yocto 环境来生成 SDK 和 FFT demo。
初始化 Yocto
$ mkdir imx-yocto-bsp$ cd imx-yocto-bsp$ repo init -u https://source.codeaurora.org/external/imx/imx-manifest -b imx-linux-rocko -m imx-4.9.123-2.3.0-8mm_ga.xml$ repo sync
修改 local.conf.org,添加下面内容
IMAGE_INSTALL_append = " devil devil-dev imx-gpu-sdk libzip"CONF_VERSION = "1"TOOLCHAIN_TARGET_TASK += " devil-dev imx-gpu-sdk libzip"
编译 文件系统和交叉编译工具
$ bitbake fsl-image-gui$ bitbake meta-toolchain
提取文件系统文件,其中包括编译所需的头文件等
$ runqemu-extract-sdk ~/imx-yocto-bsp/build-imx8qxpmek/tmp/deploy/images/imx8qxpmek/
fsl-image-gui-imx8qxpmek-20190315085707.rootfs.tar.bz2 ~/imx8qxpmek-rootfs
添加 OpenCL 头文件
可以从下面下面链接下载 https://github.com/KhronosGroup/OpenCL-Headers,解压后将其复制到 ~/imx8qxpmek-rootfs/usr/include/
建立 libzip 库软链接
$ cd ~/imx8qxpmek-rootfs/usr/lib$ ln -s ../../lib/libz.so.1.2.11 libz.so.1
Colibri IMX8X SD 卡文件系统构建和烧写方法请参考这里。
OpenCL FFT demo 编译
NXP 的 DemoFramework 提供了大量基于 GPU 的demo,包括使用OpenCL、OpenGL 和 Vulkan,用户通过这些 demo 快速了解 iMX GPU 的开发使用方法。下载地址 https://github.com/NXPmicro/gtec-demo-framework
Toradex Colibri iMX8X 的 imx-4.9.123 Linux BSP 采用 DemoFramework v5.1.1。下载后解压,并进入该目录,设置编译的环境。
$ cd gtec-demo-framework-5.1.1$ pushd ~/imx-yocto-bsp/build-imx8qxpmek/tmp$ source environment-setup-aarch64-poky-linux$ export ROOTFS=~/imx8qxpmek-rootfs$ export FSL_PLATFORM_NAME=Yocto$ popd
编译 FastFourierTransform
$ source prepare.sh$ cd DemoApps/OpenCL/FastFourierTransform$ FslBuild.py
在 Yocto 编译环境中,系统会根据依赖关系自动下载所需的软件包。
运行 FFT demo
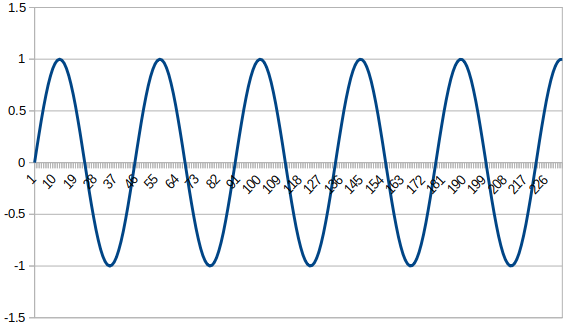
为了便于观察 FFT 结果,我们修改输入信号,使用单频率的正弦函数。例如以 44.1KHz 频率采样一个 1KHz 的信号,采样点数4096,并对采样结果做 FFT 变换。
https://github.com/NXPmicro/gtec-demo-framework/blob/master/DemoApps/OpenCL/FastFourierTransform/source/FastFourierTransform.cpp#L432
中的三角波修改正弦信号。
m_Freal[i] = m_intime[2 * i] = sin(1000 * (2 * 3.1415926) * i / 44100);m_Fimag[i] = m_intime[2 * i + 1] = 0;m_outfft[2 * i] = m_outfft[2 * i + 1] = 0;
将编译好的 FastFourierTransform 和 Content 目录以及其中的 fft.cl 文件一起复制到 Coliri IMX8X上。fft.cl 是OpenCL 内核文件。执行后生成 fft_input.csv、fft_output.csv 两个文件,分别保存输入信号和FFT运算结果。
输入信号
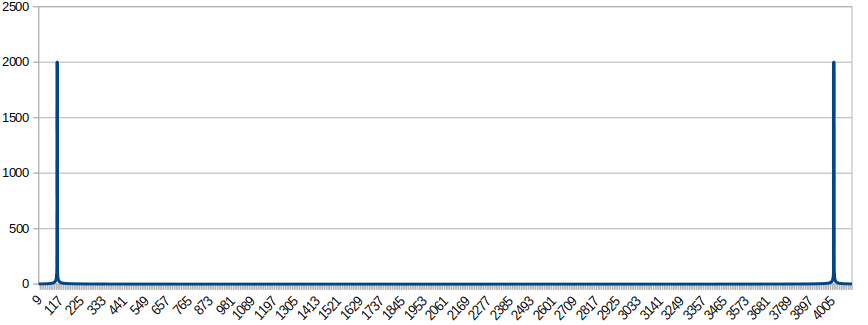
FFT 运算结果
从输出结果看,在第93点模值达到最大,该点对应的频率为44100/4096*93=1001.2Hz,即输入正弦信号的频率。
下面是demo的运行日志。GPU 会根据采样点数,分解成多个蝶型运算模型,并将每个模型并行在 GPU 上执行,从而有效降低运算时间。从日志看到每个模型耗时都在1ms以内,GPU 累计耗时为0.004604 秒。但由于是并行计算,最终的时间则是小于该值。
Compiling radix-2 FFT Program for GPU...creating radix-2 kernels...Creating kernel fft_radix2 0 (p=1)...Creating kernel fft_radix2 1 (p=2)...……Creating kernel fft_radix2 10 (p=1024)...Creating kernel fft_radix2 11 (p=2048)...Setting kernel args for kernel 0 (p=1)...Setting kernel args for kernel 1 (p=2)...……Setting kernel args for kernel 10 (p=1024)...Setting kernel args for kernel 11 (p=2048)...running kernel 0 (p=1)...running kernel 1 (p=2)...……running kernel 10 (p=1024)...running kernel 11 (p=2048)...Kernel execution time on GPU (kernel 0): 0.000209 secondsKernel execution time on GPU (kernel 1): 0.000279 secondsKernel execution time on GPU (kernel 2): 0.000507 secondsKernel execution time on GPU (kernel 3): 0.000505 secondsKernel execution time on GPU (kernel 4): 0.000065 secondsKernel execution time on GPU (kernel 5): 0.000550 secondsKernel execution time on GPU (kernel 6): 0.000457 secondsKernel execution time on GPU (kernel 7): 0.000534 secondsKernel execution time on GPU (kernel 8): 0.000413 secondsKernel execution time on GPU (kernel 9): 0.000037 secondsKernel execution time on GPU (kernel 10): 0.000524 secondsKernel execution time on GPU (kernel 11): 0.000524 secondsTotal Kernel execution time on GPU: 0.004604 secondsSuccessful.
在 Apalis iMX6Q 2GB IT 模块上,我们使用 FFTW 库在 CPU 上同样进行 4096 点 FFT 运算,并将 CPU 的时钟调整至最高频率进行对比。测试代码从这里下载。
运行耗时为 12.4ms。
总结
Colibri iMX8X 异构多核构架包含 Cortex-A35、GC7000Lite GPU和 Cortex-M4。GPU 可以发挥其并计算的能力,除了实现 FFT 外,还可以用于图形处理运算和深度学习模型推理。通过 Cortex-M4实现实时数据采集,并由GPU完成数据处理,最后在 Cortex-A35 上的操作系统如Linux 完成数据保存、呈现和传输任务,以及用户交互。Colibri iMX8X 是边缘计算设备的理想平台。后续我们会向你展示更多 Colibri iMX8X 的应用开发。
記者: 胡珊逢,FAE,韬睿(上海)
コメントを投稿
Please login to leave a comment!